
I downloaded and deleted five models on a Mac mini in one day, then kept the one already sitting on the drive. The detour answered one question that decides everything else: local model tool calling is the part that breaks, and on a 48 GB machine the model has to clear two hardware limits before it can even attempt a tool. In a 2026 benchmark of local tool-calling models, Hans Kuepper of PromptQuorum found reliability rises sharply with model size, and that the smallest models drop calls or invent tools that do not exist (PromptQuorum, 2026). The model that survived both my agents was Gemma 4 12B, run through LM Studio.
The stack is the one I keep returning to: a Mac mini with 48 GB of unified memory, LM Studio as the local server, and two agents on top, Hermes Agent for chat and OpenCode for coding. The full build sits in how we built our local AI stack, and the OpenCode wiring lives in wiring OpenCode to a local model. This piece is the part where I went looking for something better at tools and learned why the obvious model was already installed.
How much context does Hermes Agent need?
Hermes Agent refuses any model with a context window below 64,000 tokens, and that one rule shaped the whole search. The Gemma 4 31B QAT cleared the quality bar and failed the memory one. Loaded at 64K it climbs toward 35 GB, which tips a 48 GB machine into swapping, so a three-sentence reply crawled at about 2 tokens per second. The 12B fits and answers fast, so it became the working default.
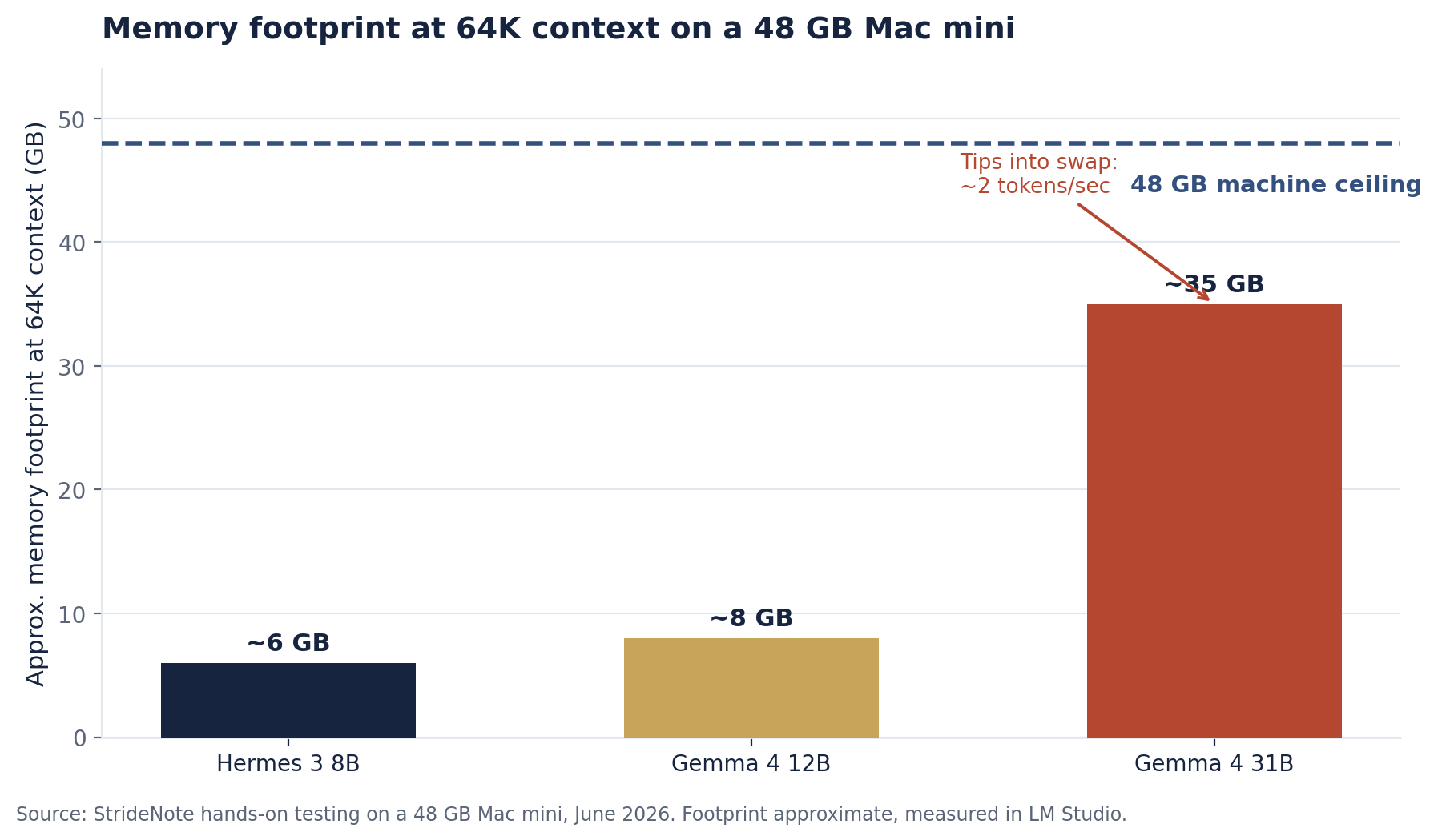
Memory footprint at 64K context on the 48 GB Mac mini. The 31B sits near the ceiling and swaps; the 12B leaves comfortable headroom. Source: StrideNote hands-on testing, June 2026.
The rule generalised to every model after it. A local model for an agent has to satisfy two limits at once: its native context has to clear the agent’s floor, and its memory footprint at that context has to fit the hardware with headroom. Miss either and the model loads but cannot work. The sizing math behind that tradeoff is in pick the right local model for your RAM.
Which small local models run on a 48GB Mac mini?
With the 12B working, I went hunting for a smaller model that punched harder, and most of the names in the news were the wrong size. DeepSeek V4 is a large mixture-of-experts model, Nemotron 3 Super is around 120B, and even GLM-5 is a 744B model. Those are cloud-class, not desktop-class. The shortlist that actually fits a 48 GB Mac is the 8B-to-32B band, which is also the subject of which local LLM should you actually run in 2026.
So I pulled Qwen3.6 27B at 16 GB, then asked a sharper question: is there a model built for the Hermes agent itself? That led to Nous Research, which makes both the Hermes Agent and an open-weight Hermes model family (Nous Research, 2024). I reached for the newest small one, Hermes 4 14B, and deleted Qwen to make room. It turned out to be built on Qwen3, whose native context tops out at 40,960 tokens, below Hermes Agent’s 64K floor. The clean fix was a model that natively clears the floor: Hermes 3 8B runs on Llama 3.1 with a native 128K window, so it loaded into Hermes at 66K with no scaling tricks and passed an identity check on the first try.
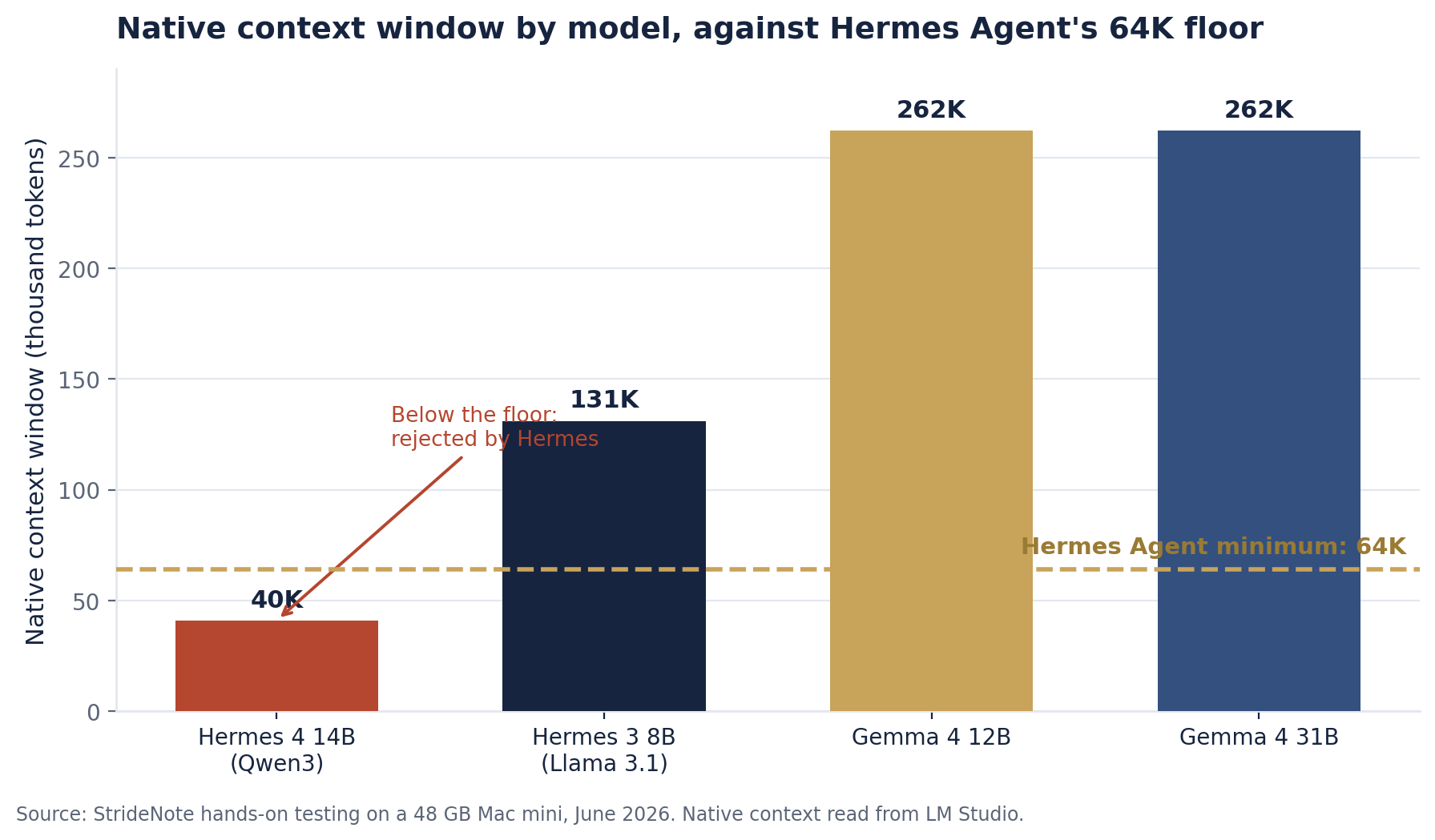
Native context window by model. Only the Qwen3-based Hermes 4 14B falls below Hermes Agent’s 64,000-token floor. Source: StrideNote hands-on testing, June 2026, native context read from LM Studio.
Why does local model tool calling fail on small models?
Then I asked the 8B to actually do something, and the real lesson arrived. In OpenCode, asked to find news on the web, it refused and claimed it could not browse, ignoring the fetch and search tools sitting in its context. In Hermes, it tried, but the agent rejected the call with “Error: Model generated invalid tool call.” The model was either skipping tools or mangling their format.
This is the failure the PromptQuorum benchmark describes for the smallest tier. Eight billion parameters sits at the bottom of the reliable range, and below the dependable threshold a model paraphrases tool calls into prose, invents tool names, or supplies arguments that fail the schema (PromptQuorum, 2026). The Hermes name on the model does not change the arithmetic. A model that cannot emit a clean tool call cannot drive an agent, and that capability is what agentic actually changed for local AI.
How does Gemma 4 12B handle tool calling in OpenCode and Hermes?
The fix was the Gemma 4 12B I already had. It ships with native tool-use training, its context window is large enough to clear Hermes Agent’s floor without extension, and LM Studio lists “tool use” as a built-in capability for it. I loaded it at 70K and tested both agents the same way.
In OpenCode, Gemma 4 12B chained two web fetches, a search and then a news site, and returned a real headline with a source link. In Hermes, it ran a full browser sequence: it searched, opened a results page, clicked, captured page snapshots, moved to a second engine, and produced a headline. Many tool calls, zero invalid-call errors. The task the 8B could not start, the 12B finished. The only cost is speed, since Hermes leans on slower browser automation while OpenCode uses a lighter fetch tool.
The full set of models I ran sits in one table below, with the two hardware tests and the tool-calling result side by side.
| Model | Params | Native context | Footprint at 64K | Tool calling in OpenCode and Hermes | Status |
|---|---|---|---|---|---|
| Gemma 4 12B QAT | 12B | 262,144 | about 8 GB | Reliable: chained web fetches in OpenCode, full browser run in Hermes, zero invalid calls | In daily use |
| Gemma 4 31B QAT | 31B | 262,144 | about 35 GB, swaps | Not evaluated, too slow at 64K | Kept on disk |
| Hermes 3 8B | 8B | 131,072 | about 6 GB | Unreliable: refused in OpenCode, invalid tool call in Hermes | Removed |
| Hermes 4 14B | 14B | 40,960 | below the 64K floor | Not reached | Removed |
| Qwen3.6 27B | 27B | not recorded | about 16 GB | Not evaluated, removed first | Removed |
Source: StrideNote hands-on testing on a 48 GB Mac mini, June 2026. Native context read from LM Studio; footprints approximate.
So I cleaned house. Out went Qwen, the Hermes 4 14B, and the Hermes 3 8B. Two models remain in about 26 GB: Gemma 4 12B as the daily driver for both agents, and Gemma 4 31B kept on disk for the rare offline job where waiting is fine.
Which local model should you run for AI agents on a Mac?
Three findings carry over, and none is about the name on the model. A local model for an agent has to pass two hardware tests first, native context against the agent’s floor and memory footprint against the machine, before quality matters at all. Tool-calling reliability is a separate test that tracks model size more than brand, so the floor for dependable agent work on this hardware is the 12B class, not the 8B. And when an error message asks for a model with a large native context, the answer is to pick one, not to fight a scaling workaround.
The smaller model I had been quietly running all along cleared every test: it fits the memory, clears the context floor, and calls tools without dropping them. The next number I want to cut is OpenCode’s own system prompt, which runs past 51,000 tokens once every connected tool is counted, because that, not the model, is what sets the context I pay for on every request.